看书大概了解了下Streaming的原理,但是木有动过手啊。。。万事开头难啊,一个wordcount 2小时怎么都运行不出结果。是我太蠢了,好了言归正传。
SparkStreaming是一个批处理的流式计算框架,适合处理实时数据与历史数据混合处理的场景(比如,你用streaming将实时数据读入处理,再使用sparkSQL提取历史数据,与之关联处理)。Spark Streaming将数据流以时间片为单位分割形成RDD,使用RDD操作处理每一块数据,没块数据都会生成一个spark JOB进行处理,最终以批处理方式处理每个时间片的数据。(多的就不解释了,百度就好了~)
首先确保你安装了hadoop和spark,在IDEA中也已入来了相应jar包。
写吧- -
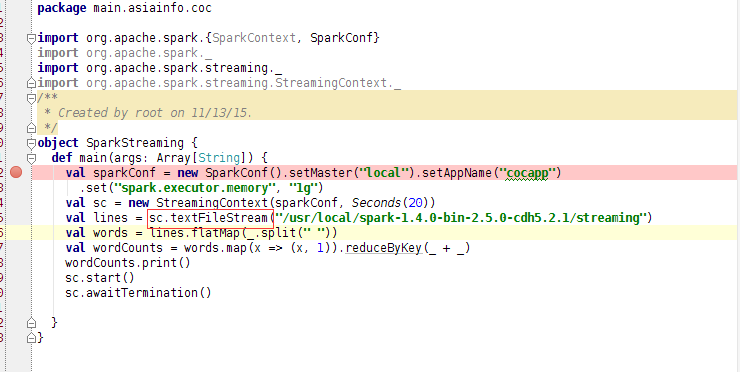
新手要注意红框部分,spark官网上给的例子是调用socketFileStream方法,这是通过socket连接远程的,倘若只在本机上测试学习,就用textFileStream读取本地文件路径,没错是路径不是文件,因为sparkStreaming是处理实时数据的,倘若直接指定一个文件,输出后是无法得到结果的。所以新建了个路径,在这里设置了Seconds(20)每20秒读取一次。随后run一下。
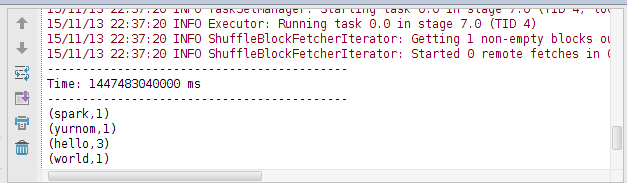
启动后,将准备好的文件cp到这个路径下,20秒过后结果就出来了,模拟了下实时数据。结束。